It is usual to have a gzipped file and need to extract from it just the few lines of text. For example, if you’re generating log files directly in gzip format (as rsyslog allows to do) it would be interesting to extract a continuous stream of uncompressed data, but starting just from the end, as the rest of the file is not interesting in that moment.
Nonetheless, gzip is a continuous stream of compressed data, and a quick search for resources immediately shows pages where the possibility of extracting data from a gzip file in this “random” way, without first uncompressing the whole file, is considered impossible.
But Mark Adler, the creator of zlib, has a little file, under the examples folder in his repository for zlib, named zran.c which shows how this could be done, without previously modifying the already compressed data. In brief, it creates “points” of access to the compressed stream of data that can be used to initialize the zlib library using the “window” of (32 kiB) uncompressed data that precedes it. The example is really clear and concise, and very easy to test.
So the only issue that rested was to write that “index” of access “points” to a file associated to the original compressed data in order to being able to quickly and efficiently (in terms of both memory and cpu) access any data in any gzip file, no matter how big it is.
With all this, I did an almost direct (but with data compression) serialization of the array data used to maintain the index of points, to disk, and wrapped the code with usable command line options. And it all worked!
The index file has the same name as the original compressed data file, with extension “.gzi” instead of “.gz“. If the extension is different (for example with .tgz files or others) the complete “.gzi” extension is added (not just the final “i“).
Also, I used stdout as the primary destination of data output because I found that this created a more usable tool. If the output must be written to a file a simple > redirection will do, but also this way some quirks like tee or others are easy (and possible)! As a side note, also stdin can almost always be used as input, though not documented. Command concatenation in linux’ shell is just too powerful to not implement it :-)
The tool is called gztool and can be found at github.
Note that there are precompiled binaries for Windows and for linux.

The only drawback to this approximation is that the index must be created first… but I changed this on the first versions, and now data extraction AND index creation occurs at the same time, so there’s no drawback in using gztool to extract data from a gzipped file, even if a full uncompression is needed, because the index is created at the same time with no time penalty. And the indexes are really small compared with the compressed data files (0.3% or much less if gztool compresses the data itself), so the space increment is negligible compared with the possible future benefits of random-access data-uncompressing.
Another feature of gztool-index files is that they can be interrupted at any moment, and will remain usable for future executions of gztool. For example, we may need to extract from byte 1 000 000 000 but we may do a Ctrl+Break at any moment:
$ gztool -b 1g myfile.gz | less
and the index file (myfile.gzi in this case) will be usable from the first to the last index point stored there, and resumable from that last point on if data beyond that point exists or is needed.
Also, parameters for tail (-t), and continuous tail (-T, as with a tail -f on a text file) are available. Note that gztool will be creating the index in background and it’ll be usable on another gztool runs, no matter when you interrupt the tailing:
$ gztool -T mybigfile.gz
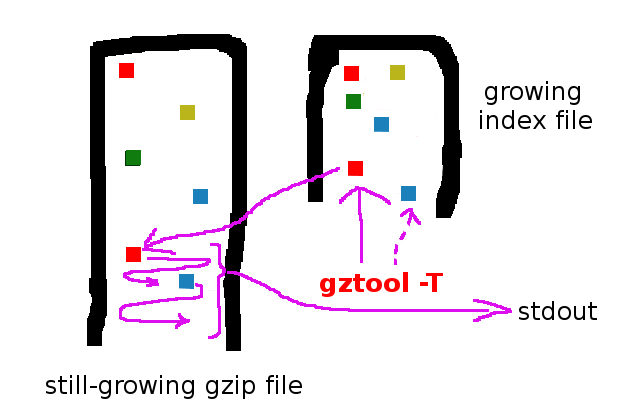
There’s also an option to Supervise (-S) a still-growing gzip file: this way, the index can be created in background at the same time that the gzip file is being created, which can be very convenient if the still-growing file is a gzipped log file created with rsyslog, for example – this way there’s no time penalty in practice for creating the index:
$ gztool -S mylog.gz &
And as this -S is creating already a mylog.gzi index file in background, we can do a continuous tail with another gztool command: there’s only one little intricacy: as gztool always tries to “complete” the indexes it touches, there’s a parameter -W to tell it not to do so, and only read (use) the index if available but to not create nor modify it if it already exists. And so:
$ gztool -WT mylog.gz
this would print to screen (stdout) a continous stream of uncompressed data written compressed to mylog.gz as it grows, and with no time nor cpu penalty!

Well, you can find more examples of use at github repository for gztool.
gztool is also able to treat gzipped files with more than one stream on top of the other, which are possible in principle, though rarely used (for example by mistake, after the file is closed, but later more compressed data is added with >> or something like that).
Nonetheless, note that for example rsyslog can produce gzipped logs which can be composed of multiple gzip streams, using the veryRobustZip parameter.
gztool can also correctly manage bgzip files, which are basically finished gzip streams of 64 kiB data compressed one after the other. Note that bgzip is very convenient as compressed format: can be decompressed directly by gunzip, and the data is almost directly randomly accessible: bgzip can also create indexes (which are really really small: just two numbers per entry point) for random access… and they also have a gzi extension! I’ve made this on purpose: gztool-index files should be ignored by bgzip, and gztool won’t recognized bgzip indexes as usable. More details on gztool-index file format at readme on github.
And… what’s the appearance of a .gzi file constructed on an already compressed gzip file? Well, as it uses mostly 64-bit long integers, there’re a lot of zeros, but most of the content correspond to the compressed windows, and so the CV is only a little worse than for its gzipped companion:


Note that in this example, the index file b.gzi has been generated with -s 1 (and span between index points of 1 MiB of uncompressed data) instead of the default -s 10 just to generate a bigger index. With -s 10 it would occupied only 62 kiB, instead of 618 kiB.
But gztool can also generate the gzip file from the uncompressed data (gztool -c), and in this case the produced index is really tiny (almost as space-efficient as the one produced with bgzip) because the compressed data is gzip-sync’d at every access point so the window of data required has size zero: this way the index is just a set of a few numbers per access point, and so the circle for it is like a cheese full of holes:

Again in this case this index file contains 10 time more access points than if it were generated with the default -s 10. Anyway note that to provide 1 access point for every 1 MiB of uncompressed data (61 points in this case) just 1 kiB and a half is needed:
$ gztool -l b.2.gzi
ACTION: Check & list info in index file
Checking index file 'b.2.gzi' …
Size of index file: 1504 Bytes
Number of index points: 61
Size of uncompressed file: 62914560 Bytes
1 files processed
